Hace unos días os contamos acerca de DeepSeek R1, el muevo modelo LLM especializado en razonamiento que en muchos aspectos llega incluso a superar las capacidades y calidad de respuestas de ChatGPT, hasta ahora la reina de las IAs de chat. DeepSeek lo hace muy bien y además es verdaderamente open source, pudiendo instalar sus modelos localmente en tu ordenador para utilizarlos indefinidamente y sin limitaciones. Está teniendo tanto éxito que en su App para iPhone, que hace todo online, se nota que están teniendo problemas de capacidad. Demasiadas personas intentan utilizarlo al mismo tiempo.

Su salida ha hecho que las acciones de Nvidia y otras empresas tecnológicas como Google hayan bajado muchísimo, una importante caída que ha causado pérdidas de miles de millones de dólares de capitalización. La razón es que DeepSeek consigue hacer lo mismo que OpenAi o Gemini, aparentemente, con menos de 6 millones de dólares, y utilizando muchos menos recursos. Lo cierto es que el modelo de DeepSeek que puede hacerlo mejor que ChatGPT pesa más de 400 GB, y eso hay muy pocas personas que puedan cargarlo en la RAM de su ordenador en casa, pero las versiones más reducidas de su modelo también funcionan muy bien y sí se pueden instalar en cualquier ordenador, o incluso en una Raspberry Pi 5 con 8 GB de RAM. No es que vaya muy rápido, eso es cierto, pero funcionar, funciona. Como asistente de programación, por ejemplo, es increíblemente útil y certero.
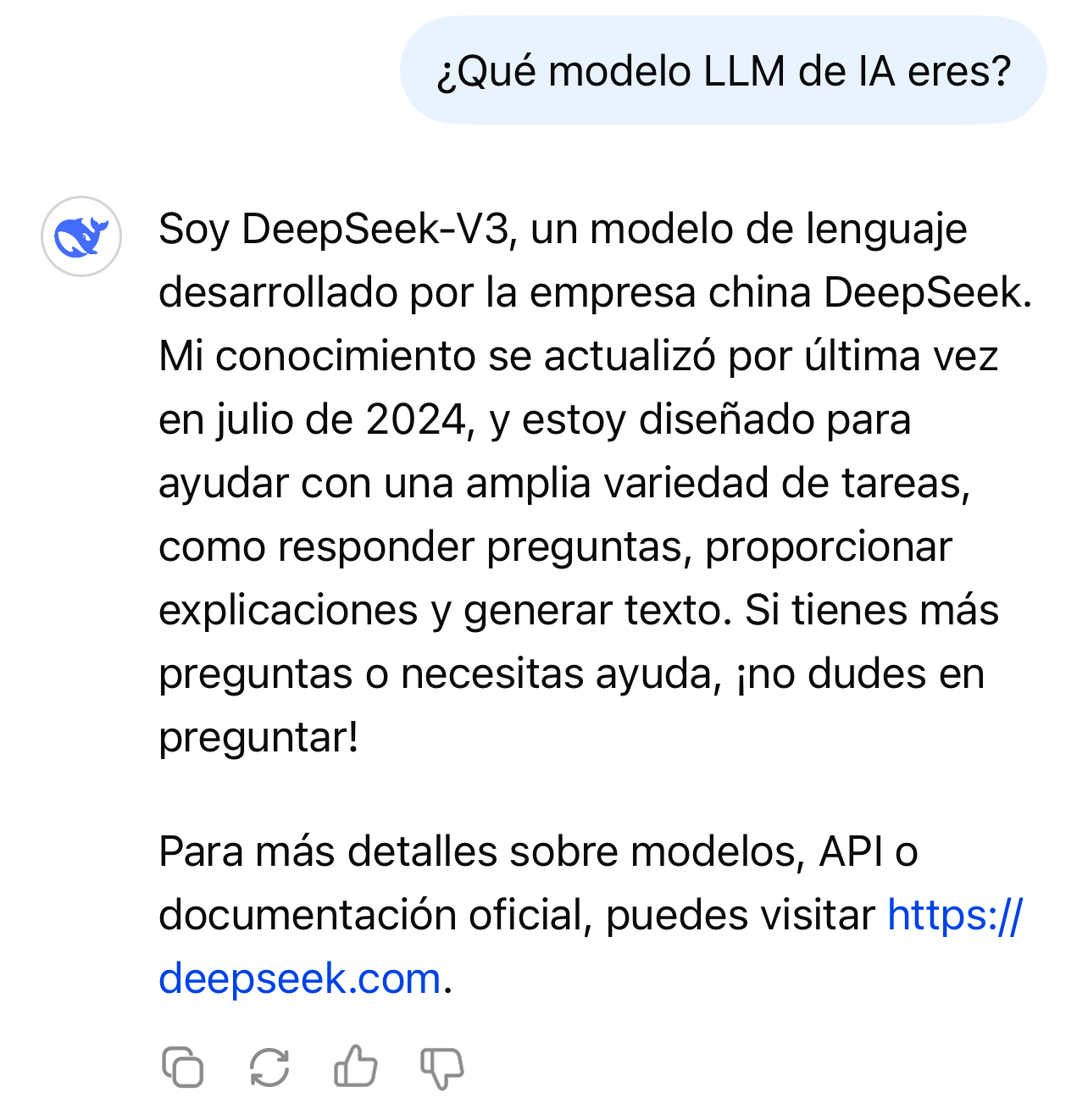
Sin embargo, parece que hay sombras de que en DeepSeek han hecho un poco trampas para entrenar su modelo y conseguir tan buenos resultados; En el Financial Times cuentan que en OpenAI piensan que han utilizado las respuestas de ChatGPT para entrenar a Deep Seek. Este proceso, que es habitual en todas las empresas desarrolladoras de modelos LLM y se llama distillation, algo así como destilación, está prohibido por los términos y de uso y condiciones de OpenAI. Esta sospecha la han tenido también otros usuarios que al preguntar a DeepSeek qué modelo utiliza, contestaba ChatGPT erróneamente… o supuestamente erróneamente, porque al menos en nuestras pruebas, nunca hemos conseguido que conteste algo así.
Por ahora no hay denuncia ni nada publicado más allá de ese artículo de pago del Financial Times, así que no se sabe si todo esto es realmente cierto o no. Habrá que esperar mientras se clarifican las cosas, o, quizás, habrá que dejar de invertir tantos miles de millones en el desarrollo de estas mal llamadas IAs y dejar que explote esa burbuja para hacer las cosas con un poco más de sentido común. Por otro lado, OpenAI, que ahora de Open no tiene más que el nombre, ha entrenado sus modelos con datos públicos pero con derechos de autor y copyright en millones de webs, vídeos de YouTube y vete tú a saber qué más, y ahora que quizás otra empresa ha hecho lo mismo con ellos, no les gusta. Parece que la carrera de las IAs va a ser bastante entretenida.





















